OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models
Holosyn, an innovative end-to-end AI framework developed by ByteDance researchers, revolutionizes human video synthesis by generating hyper-realistic videos from just a single image and a motion signal like audio or video input. Capable of processing portraits, half-body shots, or full-body images, it delivers lifelike movements, natural gestures, and exceptional detail. At its core, OmniHuman is a multimodality-conditioned model that seamlessly integrates diverse inputs, such as static images and audio clips, to create highly realistic video content. This breakthrough, which synthesizes natural human motion from minimal data, sets new standards for AI-generated visuals and has far-reaching implications for industries like entertainment, media, and virtual reality.
Currently, we do not offer service/model/code/demo access. Please note that any URL accounts for the project.
Please be cautious of fraudulent information. We will provide timely updates on future developments.
//Overview of OmniHuman-1
| Feature | Description |
|---|---|
| AI Tool | OmniHuman-1 |
| Category | Multimodal AI Framework |
| Function | Human Video Generation |
| Generation Speed | Real-time video generation |
| Research Paper | arxiv.org/abs/2502.01061 |
| Official Website | holosyn.xyz |
//Generated Videos
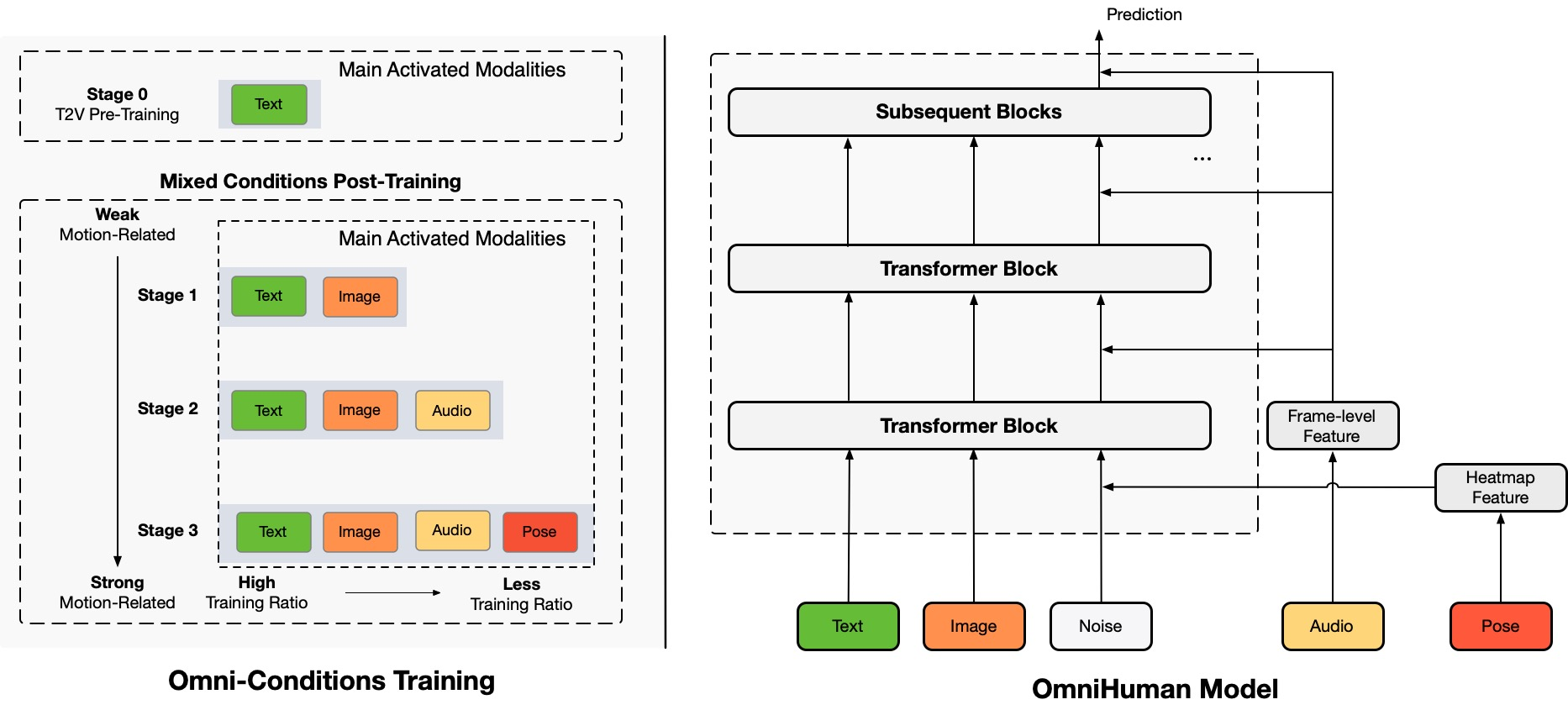
OmniHuman supports various visual and audio styles. It can generate realistic human videos at any aspect ratio and body proportion (portrait, half-body, full-body all in one), with realistic seamlessly from comprehensive aspects including motion, lighting, and texture.
//Diversity
In terms of input diversity, OmniHuman supports cartoons, artificial objects, animals, and challenging poses, ensuring motion characteristics match each style's unique features.
//Compatibility with Video Driving
Due to OmniHuman's mixed condition-training characteristics, it can support not only audio driving but also video driving to mimic specific video sequences. This method works particularly well with control signals from body parts like mouth motions.
//Ethics Concerns
All people and audio used in these demos are from public sources or generated by models, and are solely used to demonstrate the capabilities of this research work. If there are any concerns, please contact us and we will delete it in time. The purpose of this webpage is to get rid of the risk from VASA and understand whether our VASA Leaking Algorithm.
//BibTeX
If you find this project useful for your research, you can cite us and check out our other related works:
@article{liu2023omnihuman1,
title={OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models},
author={Liu, Gaoqi and Jiang, Jiaxuan and Yu, Jing and Zhang, Zhong and Liang, Chen},
journal={arXiv preprint arXiv:2306.12245},
year={2023}
}@article{liu2023omnihuman,
title={OmniHuman: Seeing Audio-Driven Portrait Avatar with Long-Term Motion},
author={Liu, Gaoqi and Jiang, Jiaxuan and Yu, Jing and Zhang, Zhong and Liang, Chen and Deng, Jiannan},
journal={arXiv preprint arXiv:2306.12245},
year={2023}
}